Riak Replication and Partition原理解析
最近要做一个Riak的培训就顺便写几篇关于Riak的介绍,这里主要涉及到一些Riak的一些核心原理。这篇主要介绍Riak的Replication/VNode/Consistency Hashing方面的东西。
Riak与一致性哈希算法
Riak通过一致性哈希算法将物理的多个Riak node虚拟化成数个虚拟节点形成一个环状均匀的分布。如下图:
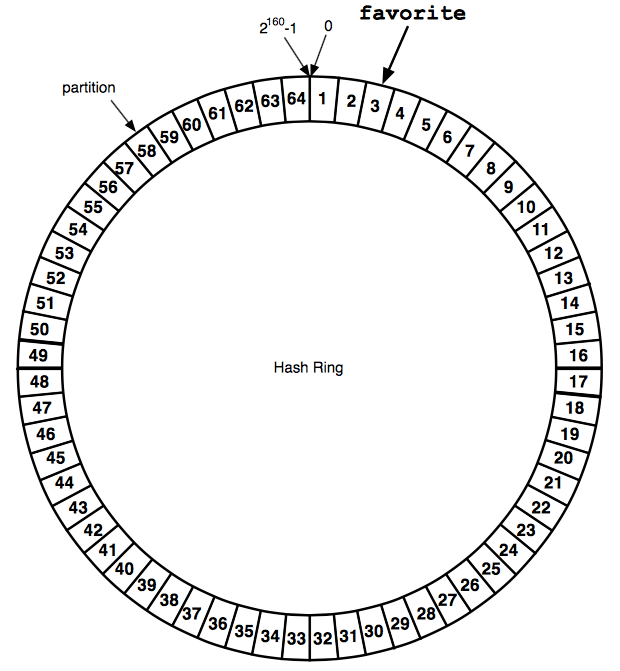
A = [1,6,11,16,21,26,31,36,41,46,51,56,61]
B = [2,7,12,17,22,27,32,37,42,47,52,57,62]
C = [3,8,13,18,23,28,33,38,43,48,53,58,63]
D = [4,9,14,19,24,29,34,39,44,49,54,59,64]
E = [5,10,15,20,25,30,35,40,45,50,55,60]
A/B/C/D/E 分别代表物理的Riak node.
Riak Replication处理机制
-
1- 在说Replication之前我们需要先了解CAP Theorem
-
2- Riak 提供了Tunnable CAP机制,可以在bucket级别去设置N/R/W来灵活的调整一致性和可用性。下面解释下N/R/W在R内部的处理:
N -> 每次数据写入要在多少个虚拟节点上做replication. R -> 每次读取要有多少个虚拟节点成功返回. W -> 每次写入要写多少个虚拟节点并成功返回. DW -> 每次写入要有多少个虚拟节点成功返回并写到硬盘上,一定程度上会影响请求响应. PW -> 每次写入要在多少主节点成功返回. PR -> 每次读取要有多少个主节点成功返回. -
3- 具体的Riak处理流程可以看如图:
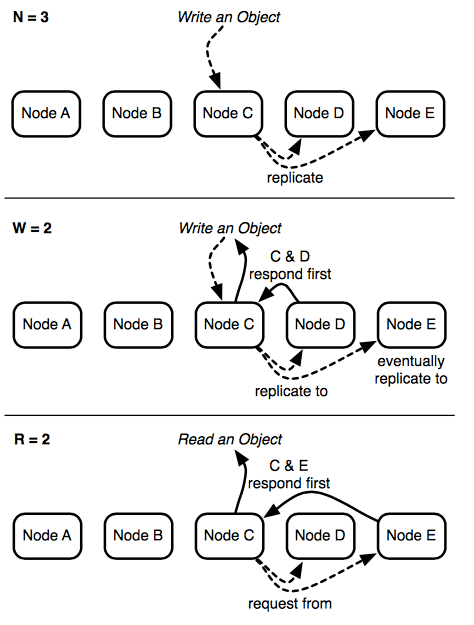
关于主节点的解释:Riak在每次读写的时候都会根据用户请求数据的bucket+key生成一个hash,Riak根据这个hash值得出一个虚拟节点的preference list, 把最前面的N个作为主节点。如果主节点不可用,则去找secondary vnode.
- 4- 现在我们可以来讲Riak的Replication机制了如图:
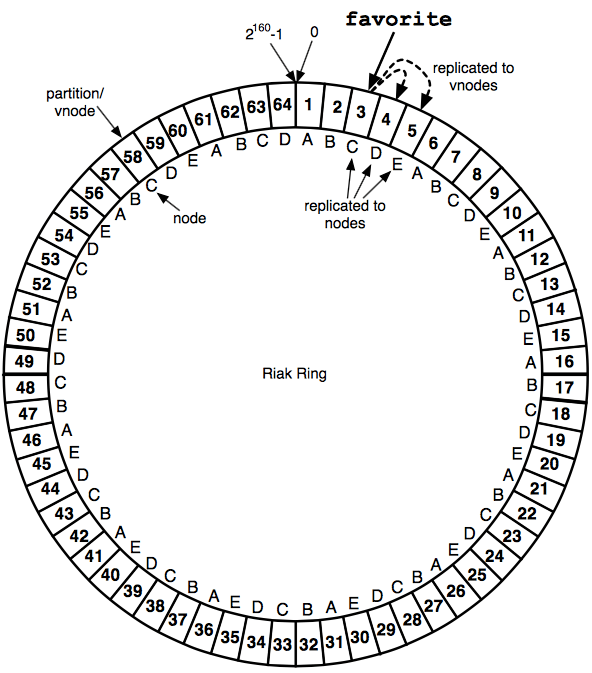
假设: N=3
我们有一个叫做favorite的数据对象,现在将它存入Riak,假设3号虚拟节点存储了这个数据,Riak会将这一分数据复制到prefere list中的另外的2个虚拟节点中,就像上图中的4/5.这里我们发现C/D/E正好是在不同的物理Riak node上,这样任何一个或两个物理节点down掉也不会影响Riak的可用性。这样就保证了high availability.
推荐一些参考资料
- Riak-Replication
- 这次培训的Keynote → Introducing Riak
- Call me maybe: RICON East talk
- Call me maybe: Carly Rae Jepsen and the perils of network partitions
07 November 2013 Suzhou, China注意这里并不能保证上面3 replications完全在不同的物理节点上,这是由Riak选取虚拟节点的机制决定的. Cherrs!
Powered by Jekyll