ZFS Raidz 分析
ZFS的RaidZ是在我们日常中会比较多的用到,值得我们来一起探讨和深入研究下,在开始之前我们先看几个ZFS的基本概念,方便我们理解。
Virtual Device介绍
先介绍下ZFS的vdev的概念,对我们更好的理解ZFS raidz会有帮助。ZFS中有2中类型的的vdev:
- 物理vdev: 我们把它看成物理磁盘即可
- 逻辑vdev: 一组物理磁盘的集合
如下图, 显示了一个最基本的2个mirror的zpool的配置,4个物理vdev分成2组构成2个逻辑vdev, root vdev比较特殊每个zpool都会有一个, 所有这root vdev的直接孩子叫做top-level vdev, 这里即: M1/M2 这2个逻辑vdev:
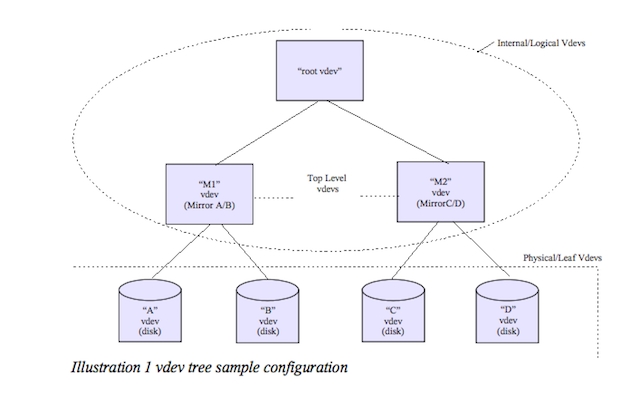
这里再介绍一个label的概念,这里每个物理vdev上都有一个256K的数据结构,我们叫做vdev label,例如: A这里物理设备中的label包含了A,B 和M1的元数据信息。vdev label的目的是用来验证数据的完整性和物理设备的可用性。这个label在每个物理vdev上提供了4份拷贝的冗余,如下图:

只要一个物理vdev加入到pool里面,zfs就会生成4份label copy, 分别位于物理vdev的头部和尾部, 这里为什么要分别放在头尾?
主要目的是为防止数据的损坏,而数据损坏一般发生在磁盘的连续的chunk上,把它们放到不连续的位置可降低数据损坏带来的风险。前面blog提到的uberblock的数据其实也是存在这里vdev label内部。
Raid-Z Striping
有了上面的基本概念,我们来看下ZFS Raidz的全条带写入,以及它的数据在物理磁盘的分布。如下图:
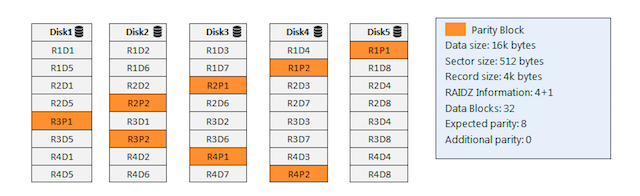
- 5个盘组成raidz-1的整列,16K的数据,物理磁盘block是512byte, recordsize是4K。
- 这里16K/4K=4个records, 每个record是4K, 4K/512byte=8个block, 所以每个record会跨2行,每行都需要一个校验数据block(R1P1, R1P2, …)
- 这里16K的数据是在一个transaction写入。
这里有人可能会问,如果其中的一个数据块损坏,raidz有self healing的特性,如何修复?
- A: 上层应用读取数据,ZFS将这些数据块组和起来,然和通过比较metadata中的checksum值来判断,如果不匹配checksum, ZFS会找到损坏的block, 通过奇偶校验数据将它恢复,然后再组合重建,返回给应用,所有的过程都有ZFS自动完成不需要依赖任何的特殊硬件。
- A: 对于raidz-1来说, 另外一种场景是一块磁盘失效,ZFS同样通过上述处理过程来self-healing.
Raid-Z Parity
Raidz的奇偶校验数据和磁盘block相关与数据的条带是没有关系的,这需要注意如下图:

这里我们看最后一个颜色条带(1 parity + 4 data + 1 parity + 4 data + 1 parity + 3 data)。
从上图中我们可以看到有的数据块是X是padding,可能会问为什么会产生这样的padding据块?
答案是Raidz整列方式分配block是按照(p+1)的倍数来分配,p代码奇偶校验盘数量,所以每个record数据在磁盘的block的分配都是(p+1)的倍数。这样做的目的是当一个数据块释放的时候,至少可以用来再分配一个最小的数据(1 data block + 1 parity block)。不会出现一个最小的数据单位都分配不了导致磁盘空间浪费。
Raid-Z Parity Overhead
关于raidz 奇偶校验数据的overhead,我们来做个实验会看的比较清楚, 实验步骤如下:
- 创建一个4(3+1)个数据盘的raidz-1的阵列, 磁盘的block是4K, 非常巧我的服务器正好有这个环境
- 将recordsize设置成4K, 写入16K的数据,我们看下有多少奇偶校验数据?
环境如下:
$ zpool status #4个盘raidz-1
pool: zones
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zones ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
c1t1d0 ONLINE 0 0 0
c1t2d0 ONLINE 0 0 0
c1t3d0 ONLINE 0 0 0
c1t4d0 ONLINE 0 0 0
logs
c1t0d0 ONLINE 0 0 0
$ echo ::sd_state |mdb -k | grep phy_blocksize #磁盘的block size (0x1000 = 4K)
un_phy_blocksize = 0x1000
un_phy_blocksize = 0x1000
un_phy_blocksize = 0x1000
un_phy_blocksize = 0x1000
un_phy_blocksize = 0x1000
$ zfs create zones/sdc # 创建一个sdc的dataset
$ zfs set recordsize=4K zones/sdc # 将recordsize设置成4K
$ zfs get recordsize zones/sdc
NAME PROPERTY VALUE SOURCE
zones/sdc recordsize 4K local
$ split -b 16k /usr/dict/words /tmp/ #将words文件切多个出16K小文件
$ cp /tmp/ab /zones/sdc/ #将一个16k小文件复制到dataset
$ ls -i /zones/sdc/
69 ab
到这里我们的环境就准备好了,下面用zdb看下这里16K的文件使用了多少parity?
$ zdb -dddddd zones/sdc 69
Indirect blocks:
0 L1 0:903fc6c000:2000 4000L/1000P F=4 B=1257429/1257429
0 L0 0:903fc60000:2000 1000L/1000P F=1 B=1257429/1257429
1000 L0 0:903fc62000:2000 1000L/1000P F=1 B=1257429/1257429
2000 L0 0:903fc64000:2000 1000L/1000P F=1 B=1257429/1257429
3000 L0 0:903fc66000:2000 1000L/1000P F=1 B=1257429/1257429
segment [0000000000000000, 0000000000004000) size 16K
我们看到一个数据(0x1000=4K)实际在磁盘上的大小是(0x2000=8K), 这个8K的组成是4K数据+4K parity数据,掐指一算每个4K的record都生成了一份4K的parity数据,parity数据占到了总数据的50%, 说好的20%呢?
所以说对于磁盘block是4K的场景,当你通过减小recordsize来提高随机读写的IOPS时候,要注意会有的parity数据的overhead,造成磁盘的空间使用率降低!
那我们有没有什么折中的方式降低parity数据的overhead?
结论是: recordsize = raidz磁盘数量x磁盘block大小, 从上面的试验来看是blocksize=4x4K=16K, 注意这个结论只是16K数据文件写入的磁盘空间使用率的场景。网上已经有外国友人帮忙算出了不同recordsize对应的磁盘parity的cost,具体看这里: RaidZ-1/2/3 Parity Cost
小结一下
- 在raidz阵列的情况下recordsize的大小设置是需要考虑磁盘的block大小和正对上层应用写入的数据文件大小来通盘考虑。
06 June 2016 Suzhou, China再提下ZFS是如何在无任何外部硬件支持(阵列卡NVRAM)下可以避免传统的Raid-5写黑洞的问题, 这篇ZFS的作者(Jeff Bonwick’s)的blog写的很清楚RAID-Z, 就不废话了。
Powered by Jekyll