Plumtree based Gossip Protocol In Riak Core
Gossip协议最大的问题是集群规模大了之后,为了确保每个节点都收到正确的广播消息,导致节点之间的message traffic会非常的大,有大量的冗余消息。它的优势也很明显,可以让集群无限的横向扩展。我们知道Riak Core是基于gossip协议来做分布式节点之间的通信,同时Basho的工程师Jordan West,也在不断的改善Gossip的实现, 在2013的RICON上看到他根据Plumtree的论文Epidemic Broadcast Trees,优化和改善了Riak Core内部的Gossip实现,这篇blog是RICON上的Topic Controlled Epidemics: Riak’s New Gossip Protocol and Metadata Store的一个理解和分析, 无法翻墙的朋友可以在这里下载。
说句题外话Jordan West在去Basho之前是StackMob的架构师, 关于StackMob我的上一篇blog Riak Core and SOA有提到
常见的Gossip实现策略:
- Eager Push: 节点随机选择同伴节点发送带payload的消息。
- Pull: 周期性的随机选择同伴节点去查询最新消息,如果同伴节点有新消息转发回查询节点。
- Lazy Push: 当一个节点第一次收到一个消息,随机选择同伴节点发送消息ID(这个消息不带具体的payload),同伴节点上如果还没有这个消息,同伴节点会去pull这个消息。

这里Pull/Push的策略实际上是一个消息可靠性和冗余的一个权衡,因为Eager push实际消息的延迟会比较低,但会造成比较多的消息冗余。Pull和Lazy Push的策略,正好相反,会有比较多的消息请求来回,但消息的冗余比较少。Plumtree的实现实际上是Eager push和Lazy Push的一种混合策略。
Plumtree在Riak Core中的实现
正常工作场景
Riak Core中基于Plumtree的Gossip协议实现主要是在Module:riak_core_brodcast, 就600多行代码,实现了一个基于gen server的self healing的spanning tree(通过不同的物理节点基于plumtree消息协议自动构建), 具体发送策略可以看init_peer/0, 这里根据节点数量的不同提供了3中机制,分别是直接点对点/环状/Spanning Tree的方式, 从源码来看message的内容对开发者是透明的,唯一的要求是需要有唯一的消息ID. 下面主要看看具体的plumtree实现。
举例来看,如下图:

假如有5个节点,会在每个节点上定义eager/lazy/msg sets(可以看代码和stat record的定义), 通过init_peer/0,来初始化eager/lazy sets, 接着我们看消息如何广播:
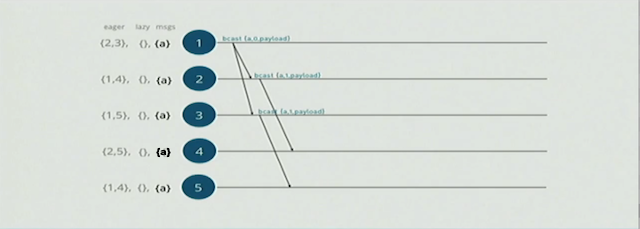
这里我们可以看到1节点会主动广播消息给eager sets里面的{2,3}节点,这里的eager消息是vclock 和payload的combination,为了解决消息的冲突每次操作都会vlock都会increment, 节点{2,3}会收到消息并更新,接着节点{2,3}分别将消息广播给,它自己的eager set的节点。
注意:如果节点的eager set里面有source节点,比如1, 它会被忽略掉,不会再广播回去,这是合理的。
这里有个比较特殊的地方是,当3节点向5节点广播eager消息的时候,我们发现3节点不在5节点的eager sets里面,这是5节点会将3节点加到他的eager sets里面,如下图:
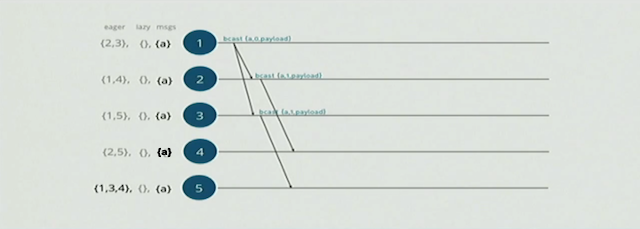
接着节点{4,5}会继续发送消息给他们的eager sets, 如下图:
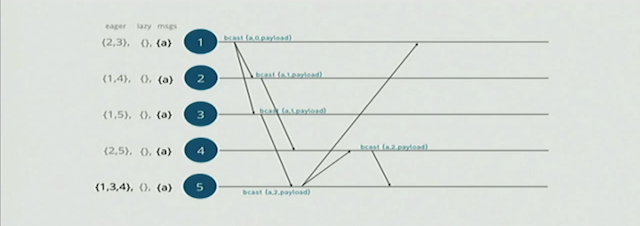
这里我们发现,node-2和node-5都向node-4发送了eager 消息,实际上跟新确是用的node-5的消息,实际上这是根据vclock merge出来的结果。
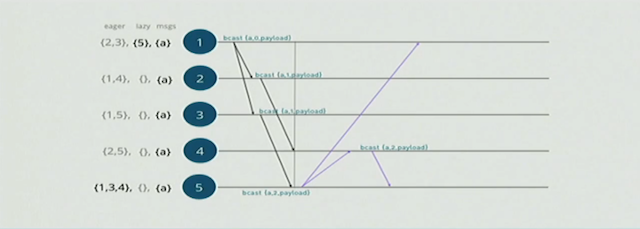
如上图,竖线的右侧的消息传递其实都是冗余的,所以当node-1接收到来自node-5的消息,会将node-5加入到node-1的lazy sets里面。之后node-1会发送一个prune的消息给node-5,告诉node-5将自己放到lazy sets里面,如下图:
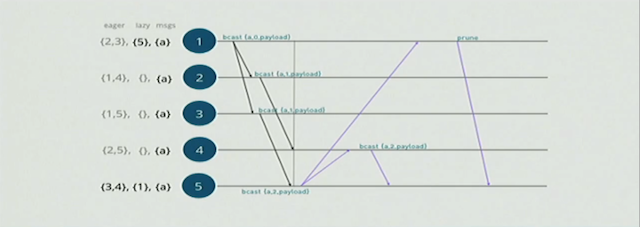
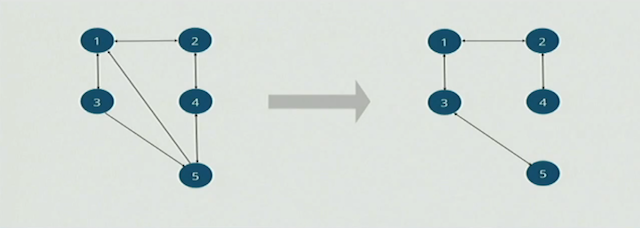
同样的处理发生在node-4和node-5之间,他们相互把对方加入到自己lazy set里面. 最后每个节点的eager/lazy sets的结果如下图:

通过如上的消息传递和修建,riak core会生成一个基于spanning tree的overlay网络结构。
单点失效场景
下面看下单点失效的场景,riak core的gossip如何处理, 接着上面的正常场景的例子,如果node-3 down掉,如下图:
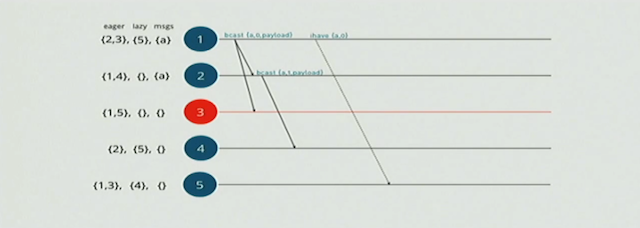
node-1依旧发送eager消息给node-2/3, 但node-3挂掉,eager消息到不了node-5, 这里我们返现node-5在node-1的lazy sets里面,这是node-1还会发送一个ihave的message给node-5, 这个message不带payload, 告诉node-5我有这个消息,你是否需要?
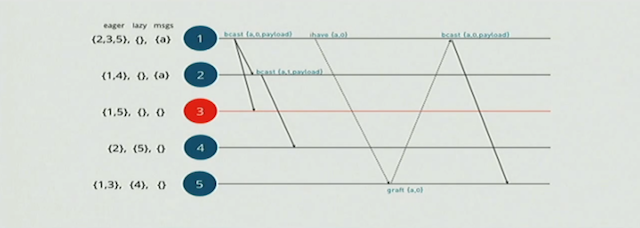
这里有2中情况,如果node-5,不需要这个消息则直接ignore掉,需要的话node-5发送一个graft的message给node-1, node-1将这个消息广播给node-5, 同时将node-5加入到eager sets.
同样的node-4里面的lazy sets里面也有node-5, 所以node-4也会发送一个ihave的消息给node-5,所以在单点失效的场景下,会生成新的spanning tree的overlay网络,如下图.
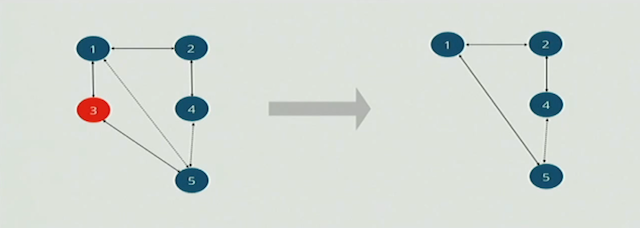
多点失效场景
假如遇到多点失效或者网络split, 如下图当node-3 down, node-5发生网络partition, 这样导致的情况是node-5将丢消息,Riak Core的gossipe如何处理?
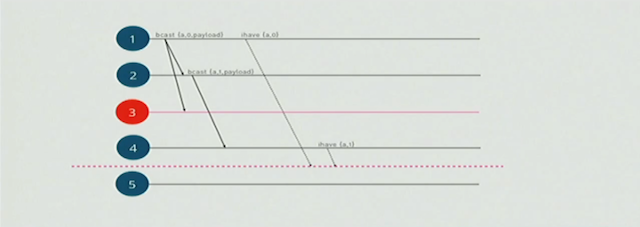
在riak_core_brodcast模块内部实现了一个outstanding sets用来存储所有的lazy消息(ihave消息),用于在将来的某个时刻发送,当收到graft ack或者ignore的应答的时候,将这个消息从outstanding sets中删除, 这样可以控制集合消息的无限增加。
这里从Basho内部的测试数据看可以容忍70%的节点失效而不丢消息!
Plumtree 数据指标
2个plumtree比较关键的数据指标:
- Relative Message Redundancy (RMR) 相对消息冗余。
- Last Delivery Hop (LDH)
这里就不具体介绍了,plumtree的论文链接里面有详细的介绍。
一句话总结
实际上Riak Core 实现的是Self Healing的Spanning Tree, 当Eager Push 断开的情况下,通过Lazy Pull来修复通信。
参考资料
- Basho - Data Dissemination
- Thicket: A Protocol for Building and. Maintaining Multiple Trees in a P2P Overlay
- Epidemic algorithms for replicated database maintenance
Powered by Jekyll