Riak Core And SOA
此篇blog是对RICON 2013的一个来自StackMob工程师的Share Using Riak Core to Manage Distributed Services的一些个人思考和解读,此YouTube链接需要翻墙,无法翻墙的朋友可以直接在这里下载.
关于StackMob
先说下视频中Stackmob这家公司,他们主要做Mobile端的BAAS(Backend As A Service),主要面向mobile开发人员,通过用户提交mobile的服务端代码,提供API的平台,后来不久就被Paypal收购, 整个服务被关闭。Paypal只用了4个月使用这个系统重构了整个mobile业务的服务端。
Riak Core的应用场景
我们对Riak Core的一般理解都是做分布式的KV的存储和缓存,消息队列等,其实Riak Core 最擅长的是根据Key来快速的定位到服务(内部依赖于一致性hash的特性),封装了所有的分布式系统需要处理的scale/distributed/fault tolerance的处理细节,能够快速的帮助我实现分布式高可用的应用。Riak Core提供了很好的对独立服务管理功能, 能够应对多租户的环境,用户的具体服务/数据对开发人员的角度来看是透明的,这样就可以很方便的去开发各种分布式应用服务。更细节的riak core的介绍可以看我的上一篇blog Riak Core 解析.
Riak Core和服务
从StackMob的案例来分析,Riak Core的后端不再是eleveldb或者erockdb这样的存储服务, 而是用户的application service.里面运行的是用户代码, 暴露具体服务。由VNode来维护用户的服务整个生命周期(starting/service request/shutting down 等),不同类型的vnode可以管理不同类型的用户服务。如下图:
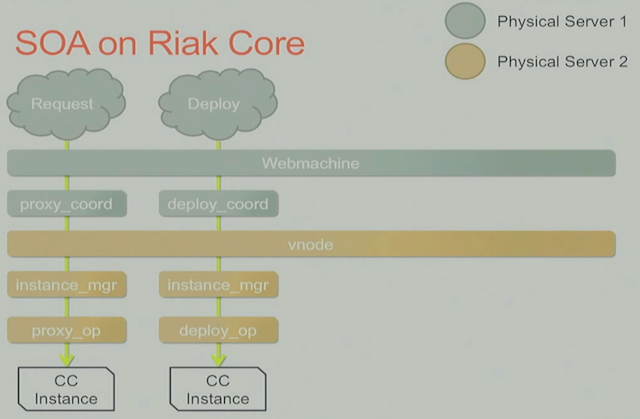
如何让Riak Core知道服务的位置?
- StackMob实现了deploy的VNode, 用户上传代码的时候会调用到这个deploy的service, 从riak core的角度来看,可以将customer code service的名称作为bucket, 将用户代码的版本作为key, 由了这2个信息,riak core会根据你要部署多少个replica的数量得到一个preflist, 有了preflist下面vnode就会接管工作,将用户服务部署多个实例。当然在vnode之上会有一个FSM (N/W的配置)来协调每个replica服务的部署。
其实我们可以将这个deploy的操作简化的看成一个write的动作。
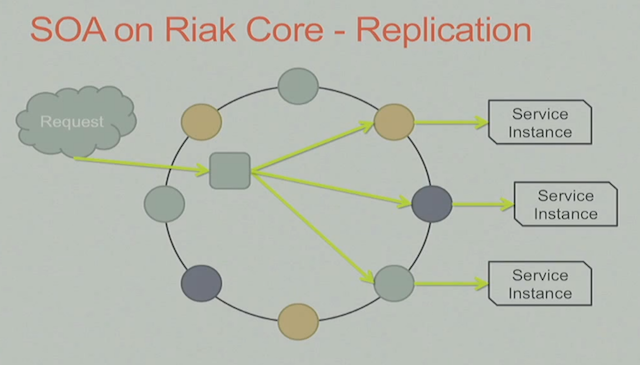
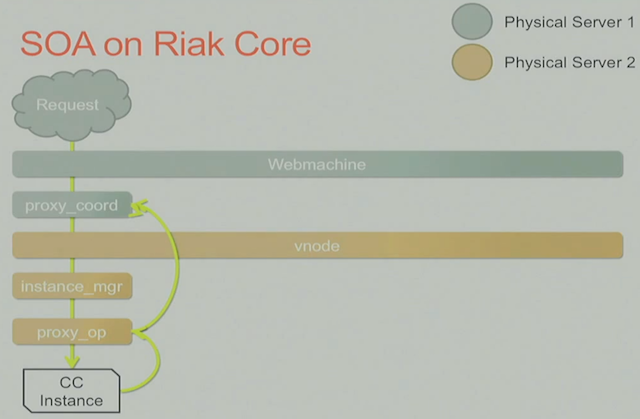
如何来服务用户请求?
每个用户请求都会带version/service id, 这样Riak Core会拿这2个信息得到Preflist, 通过fsm coordinator来协调服务(N/R的配置),具体的请求有request vnode来处理.
这里注意不同颜色代表在不同的物理服务器上。
对于service来说,我们只要一个服务请求正确,就可以直接返回,理论上R=1就可以, 如果遇到有节点失效的情况,我们可以fallback到其他的服务replica上, 如下图:
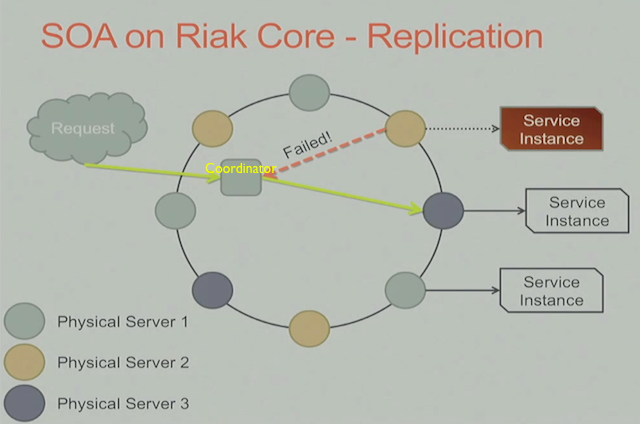
这里借助Riak Core的Read Repair 我们可以通过异步的方式有机会去修复这个down掉的节点(这里可以去restart这里服务,或者通过error message来做一些处理), 没有任何的人工干预, 又实现了高可用性。
这样我们可以很容易的让客户的服务可伸缩, 为将来业务功能提供了很多可能。
如何处理服务器单点和多点失效?
极端情况下比如network partition或则物理服务器down了, Riak Core提供了vnode的fallback和handoff功能, 依然可以保证服务可用。如下图:
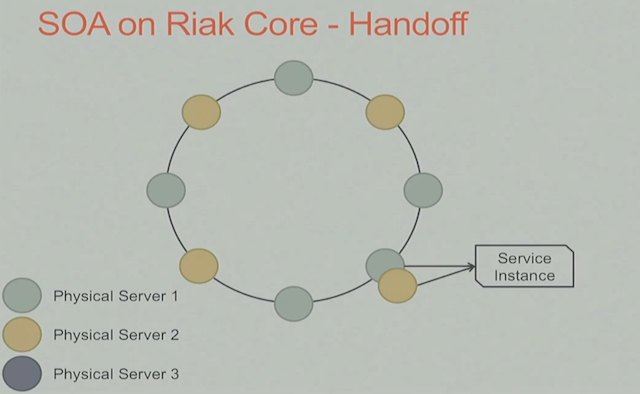
这里可用将其他vnode上的可用服务的信息(可用是ip/service/version等信息,具体情况具体分析)handoff到fallback的vnode上,这样就保证了服务的可用。服务恢复,fallback vnode将被删除,恢复的节点重新接受请求。
如何Rolling Upgrade和服务依赖?
- 服务的版本升级,对于Riak Core来说就是基于service id/version 在ring上生成一个新的hash key, 比如version=1和version=2在riak core内部来看是2个不同的数据,所有访问version=1的请求会找到指定的客户服务,并不相互影响。也不用停止任何的服务, 都是在线进行。
- 如果遇到客户内部服务依赖的场景,可用通过fsm来协调,服务之间的调用依赖。
如下图,每个服务的不同版本的调用,都是一致的, 不会出现依赖服务之间不同版本的调用混乱。
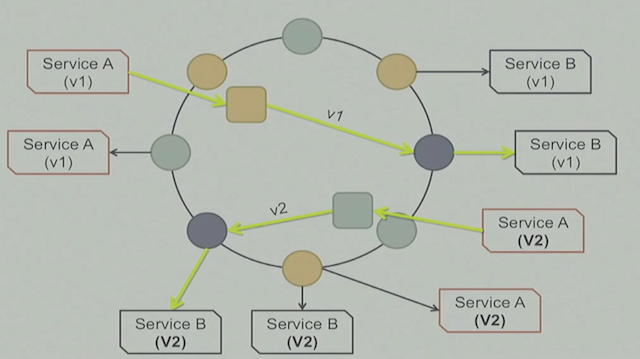
所以Riak Core一致性hash的key让rolling upgrade成为可能。
集成的关注点
- 管理API的实现(startup/shutdown等)
- 一致的服务相应,定义好reponse。
- Health Check 接口。
- FSM Coordinator 的通用实现。
19 May 2016 Suzhou, China这个blog只是对Riak Core和SOA集成的一个high level的理解,个人感觉适用于类似Coding这种网站和大型mobile服务的后端架构,无外乎是用户提交代码,这些代码可以来自S3/GitHub等,vnode服务在后端调起一个vm或者docker container, 把服务协调好,将用户代码运行服务的instance暴露出来, 同时Riak Core本身已经了提供HA。
Powered by Jekyll