Riak Core 解析
终于有时间写点博客把一些技术点沉淀下来,说下Riak Core,这方面的资料也比较少,写一点关于riak core的使用体会和它的内部原理,做了一个keynote,可以在这里下载到Build Masterless Application With Riak Core, 同时为了方便大家理解,写了一个基于Erlang OTP 18/Rebar3的demo,代码在GitHub midi, 这个代码是根据经典的try-try-try例子实现进行了重构和扩展, 可以结合代码理解会比较方便.下面具体来看为什么说Riak Core 是个好东西,以及Riak Core中的每个概念。
Why Riak Core?
Riak Core 不是一个新的分布式框架,有basho公司基于Amazone Dynamo Paper开发,最早是在riakdb里面的核心代码,后来basho工程师发现这部分代码可以抽出来,用来开发分布式应用的框架,就有了Riak Core, Riak Core基于一致性hash可提供了很好的去中心华分布式计算和存储的模型,非常容易横向扩展,提供了很好的容错和self healing的处理机制,基于riak core我们能够很快速的开发出分布式应用,包括:分布式的消息队列,分布式的kv存储服务,分布式的计算不服务等,甚至可以用它来开发基于SOA的服务调度系统(这块有时间在后续的blog来分享)。
为什么使用一致性hash?
- 一致性hash提供了很好的单调性,这个特性带来的好处是当物理节点增加或者删除的时候,需要调整的hash key能尽可能的少,只是在某增加或删除个节点与它前一个节点之间的数据需要调整。可以想象如果使用普通的hash算法来对服务器节点做hash, 那么增加或删除一个节点,说有服务器的hash key都需要重新计算, Riak core一致性Hash实现。如图:
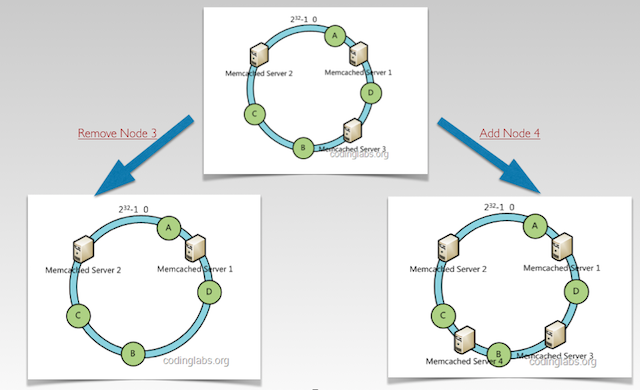
这里增加node4, 我们只需要调整node4-node3之间的hash, 删除node3我们只需要将node3-node1之间的hash调整.
- 使用一致性hash能很快速的找到,某一个hash的数据在fallback vnode上的位置。
The Ring
了解riak core的会经常看到如下图的环,这里也不免俗,说下这个ring:
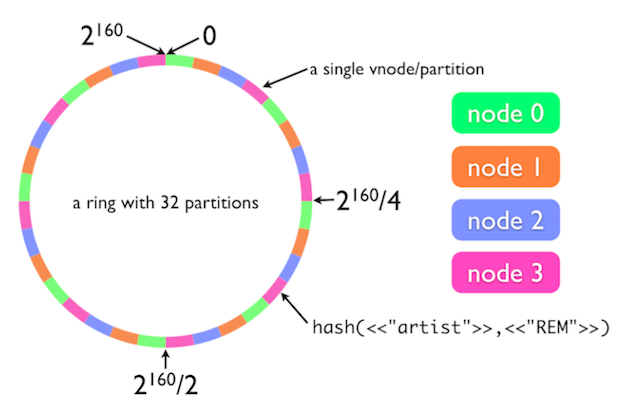
Riak Core的ring的hash值是通过SHA1的hash算法实现,如果你不想用这个算法,可以通过在配置中实现自己的hash算法。这里riak core同过一致性hash算法,将过个物理服务器节分成多个partition,每个partition是一个hash key, 尽量均匀的分布在不同的物理服务器上,默认是64个,这个值可配置,随着集群规模的扩大我们需要增加ring的partition配置。一般情况这个配置一旦设定无法更改,所有设置的时候需要考虑将来的提前量,Riak Core2.0以后提供了ring re-resizing功能,但这个开销也是非常大,所以设置的时候要谨慎.
Riak Core推荐的生产环境至少是5个物理服务器,而不是我们经常看到的3台。具体解释: Why Your Riak Cluster Should Have At Least Five Nodes
VNode
- 从上图我们看到了vnode/partition很多人可能在这个地方有疑惑,这代表什么意思? 从riak core的角度来看,vnode是在partition上的一个进程,vnode又是可以有多中服务类型的,比如计算的vnode, 存储的vnode, 不同类型的vnode代表了不同的service, 而在一个partition上可以有多个不同类型的vnode,vnode+partition的组合在ring上是唯一的。
- VNode承担了worker的作用,负责具体的实施工作,实现riak_core_vnode这个behaviour,具体的做那些事情,可以看代码midi_stat_vnode, 一个vnode还可以生成一个worker pool来生成多个worker,帮助它来异步的干活,具体实现看代码midi_crunch_vnode.
- Riak Core 提供了2种状态的vnode primay(vnode 是active状态)/fallback(单一个primary的vnode down了,会在其他的物理节点上启动一个fallback的vnode进程,来负责原来的请求)
这里需要注意的一点是: fallback的vnode所在partition还是原先primary vnode的partition,它不会生成新的partition对应的hash key.
Fallback VNode
Fallback vnode的产生是由于一个物理节点down了,这个node上的所有vnode失效,这时这些vnode都会fallback到另一台物理节点上,这些物理节点上的vnode都是fallback的状态。
当down掉的物理节点恢复,这时fallback vnode和恢复的物理节点的primary vnode会共存一段时间,直到fallabck vnode上的数据全部handoff到恢复的primary vnode上,这是所有的fallback vnode进程将被结束掉,所有的用户请求回到primary vnode.
VNode Master
看到这里你可能会问,如果有vnode挂了,怎么来协调消息? 这里vnode master就起作用了,它会知道所有的vnode的状态,那vnode master是如何知道所有vnode的状态的?每个物理服务器上都有一个vnode master的进程, 每个节点都会缓存一份整个ring的当前状态,riak core通过gossip协议,相互告知cluster中的节点,我的状态是什么,你的状态是什么,比较节点状态,更新ring缓存(riak_core_ring_manager:get_my_ring/0)来获取当前节点ring状态), 这样vnode master就知道了整个ring的状态,将message发达合适vnode.
关于N/R/W 和preflist
这里就不再废话了,可以看看之前的blogRiak Replication and Partition原理解析
Read Repaire
Read Repaire发生在从vnode读取数据,一个读请求可能会访问到不同的vnode, 这个时候从每个vnode读取的数据可能是不一致(由于单点失效或者cluster节点之间的网络中断, 后面crdt这块有详细介绍),我们会将读取到的数据merge之后,在这份数据所在的所有vnode上修复它,修复的过程可以是异步的。它的最终目的是保持数据的一致性.
实际上它的操作就是一个Passive Anti-Entropy.
Handoff
Handoff的类型:
- Ownship: 发生在新的物理节点新加入和删除,将原来vnode的数据handoff到新的vnode。
- Hinted: 发生在down掉的vnode重新恢复,fallback的vnode将数据重新handoff回原来的vnode, 这时需要注意的是handooff的vnode会做数据的merge.
- Repair: 通过代码显示调用riak_core_vnode_manager:repair/3,使用较少,开稍大,不介绍。
- Resizeing(Riak Core 2.0以后特性): 整个ring size变化以后发生(riak_core_ring:resize/0),开稍大,不介绍。
Consistency Hash Routing
我们直到riak core是通过bucket/key来做一致性hash,然后通过这个一致性hash key来路由找到对应的vnode/partition来处理具体的用户请求。如下图:
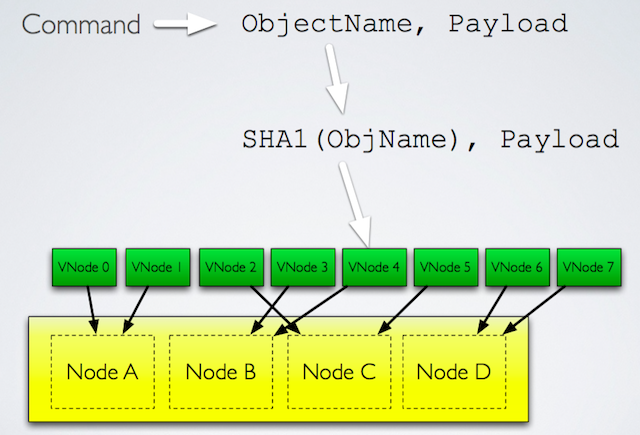
在每个物理节点上都有一个router,来处理消息的路有,这样的好处是可以避免传统中心化路由的但点问题:
那么不同物理节点上vnode的路由规则如何达成一直,其实Riak Core内部还是通过之前提到的gossip协议比较和更新每个node之间的ring的状态。
VClock
分布式的应用处理数据的一直性是个老大难问题,Riak Core本身提供了基于vclock的一致性策略,如下图来看如何使用vlock:
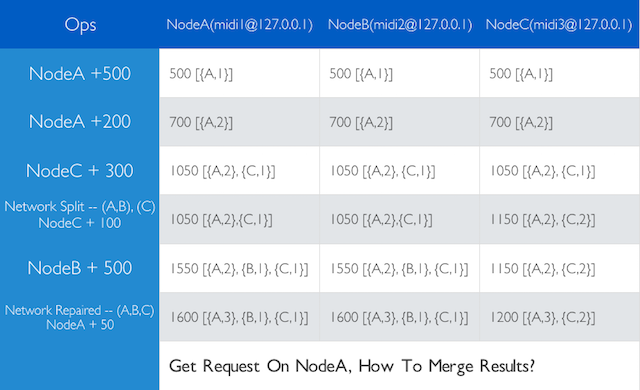
从上表我们可以看到3个物理几点组成的cluster在发生cluster split的时候,通过vlock来记录每个actor的操作,来处理数据不一致的问题。在我们的实际开发中,经常采用的策略如下:
- Last Write Wins (LWW)
- 在冲突发生的时候允许多个版本共存,由客户来决定选择哪个版本
- 采用一些封装好的类库比如statbox/riak_dt等
AAE
Active Anti-Antropy, riakdb的实现是后台的一个进程,每个一段时间执行一下,主要处理不同物理节点上的数据比较,每个物理节点上都有一个hashtree在缓存内,通过比较hashtree, 快速的找到,不一致的数据然后merge它。 riak core本身并没有提供out of box的aae接口,但是它提供了aae所有需要的基本module比如,hashtree的实现,具体的实现可以看这里:Hashtree, 实际上是根据bucket/key来hash树节点,方便快速的从树的root比较,找到不同然后更新。Riak Core Hashtree的时候默认tree width是1024, 固定3层。
Tombstones
Tombstones: 假如我们一份数据有3副本,设置成D=1,实际上只删除了1个副本,这是如果R=2正好读取到另外的2vnode, 这是数据一致性就出问题了。所以N/R/W/D的设置还是比较关键的,在服务端的开发中也是需要考虑到tombstones的问题.
对于Tombstones的场景Riak Core本身并没有提供很好的解决,需要用户自己写代码实现。可能的解决方案如下:
Riak KV的处理方式可以参考这里riak kv delete_mode
总结一下
Riak Core提供了哪些Out Of Box 功能? 如下列表:
- Physical Node cluster state management.
- Ring state management.
- Vnode placement and replication.
- Cluster and ring state gossip protocols.
- Consistent hashing utilities.
- Handoff activities, covering set callbacks.
- Rolling upgrade capability.
- Key based request dispatch.
这里顺便提下riak core实际上已经实现了基于key的这种load balancer的功能,前提是要求不同的Key(Bucket/Key).
一些不错的参考:
- Riak Core Cluster Meta
- Little Riak Core Book
- Rebar3 Riak Core Template
- CRDT LASP
- Why Vector Clock are Easy
Powered by Jekyll